Nos textos há pistas variadas, como escolha dos temas e dos termos, estilo de escrita e composição do texto, uso de imagens, etc. Mas não são fáceis de se usar por portarem uma ampla variação: muitos blogueiros ocultos saíram de sua área de conhecimento habitual para escrever um tema mais adequado ao blogue receptor (como um ou uma profissional da área de psicologia a falar sobre biologia sintética), podem ainda ter misturado com o estilo do autor do blogue receptor e incluído pistas falsas.
- 42 vezes 42 - Gene Repórter
- A dança do sexo (com vídeos!) - 42
- As Origens do Emaranhamento - Ecce Medicus
- Em algum lugar do passado… molecular - Ciência ao Natural
- Injustiça Fisiológica - Ciensinando
- Os meus dias já foram mais pequenos - Curioso Realista
- Neurobiologia Sintética - SynbioBrasil
- Por quem os sinos dobram. Longa vida a Bell. - Caderno de Laboratório
- Procrastinação, ou o porquê desse post estar dois dias atrasado - CogPsi
- Rastro de Mercúrio - Rastro de Carbono
- São Michael, padroeiro dos inventores - O Divã de Einstein
- Walt Disney, Motörhead e Fungos - Rainha Vermelha
Abaixo uma nuvem de palavras das postagens mais recentes dos blogues e dos textos publicados através do interCiência.
























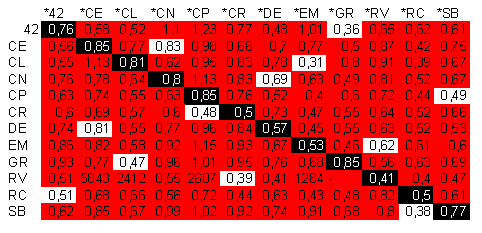
Figura 1. Nuvens de palavras dos textos dos blogues participantes (à esquerda) e do texto do blogueiro oculto (à direita) no blogue correspondente. Nuvens geradas com o Wordle.
Visualmente é difícil associar qual texto do interCiência pertence a qual blogue. Mas é possível se fazer uma comparação quantitativa, sob o raciocínio de que a escolha de palavras em um texto, em parte, está ligada ao autor (seu vocabulário operacional, seus modos característicos de expressão). Também é possível fazer uma comparação quantitativa de parâmetros de complexidade do texto: tamanho dos parágrafos, uso de parênteses, comprimento das sentenças, igualmente sob o raciocínio de que tais características não são aleatórias e revelam o estilo de expressão do autor. Na Figura 2, o resultado de uma análise comparativa de complexidade.

Em termos de complexidade*, o texto do interCiência publicado no blogue Rastro de Carbono (RC) é mais similar aos textos normalmente publicados no blogue SynbioBrasil (SB - e menos similar aos textos publicados aqui no GR). O texto no Ecce Medicus (EM) tem uma complexidade mais parecida com a dos textos do Caderno de Laboratório (CL - e mais diferente dos textos publicados no Rainha Vermelha - RV). E assim por diante.
Obviamente aqui é uma análise bastante simplificada. O tamanho amostral dos textos também é bastante limitado (10 textos normais dos blogues e apenas um texto do interCiência). É possível maior sofisticação, com calibração de pesos de cada fator - p.e., procedendo-se à maximização da verossimilhança com teste contra outros textos dos blogues - e uma amostragem mais ampla.
Veremos como esta análise se sai caso os verdadeiros autores dos textos sejam revelados futuramente. Algumas comparações podem ser feitas com outras informações:
1) a estrutura do texto publicado no RC é muito similar aos textos do SB (textos divididos por intertítulos e estes com determinado tamanho de fonte e em negrito);
2) o texto publicado no Curioso Realista (CR) está em português de portugal e, entre os participantes, é a variante usada nos textos do Ciência ao Natural (CN): a similaridade na complexidade, no entanto, não foi das maiores (na verdade, os textos de CN se aproximam mais ao texto publicado aqui no GR);
3) o texto no RV foi produzido por alguém ligado à microbiologia (além do próprio autor do RV, o autor do CR é microbiólogo): o índice de complexidade também não foi particularmente similar;
4) o único que trabalha com física entre os participantes da primeira rodada é o autor do CL; a similaridade maior é com o texto publicado no EM (que é sobre física; outro texto com a mesma temática foi publicado no próprio CL);
5) O texto publicado aqui no GR é mais similar aos textos do blogue 42 e a temática são exatamente curiosidades sobre o número 42;
6) O texto no SB foi escrito por alguém ligado à psicologia e à neurobiologia; entre os blogues participantes, são psicólogos os autores de O Divã de Einstein (DE) e de CogPsi (CP). Os textos de CP têm uma boa similaridade com o publicado no SB;
7) No CP, o texto é sobre psicologia, mas não é particularmente similar aos textos de DE (é mais similar aos textos de CR em complexidade);
8) No 42, o tema de sexo de animais e vídeos de aranhas remete ao RV; embora não seja particularmente similar no índice, a maior similaridade é com os textos do RV (e muito próximo com os do RC);
9) No Ciensinando (CE), o texto é sobre fisiologia, tema explorado no EM. Mas o valor não é muito similar, aproxima-se mais do 42.
Se essas informações estiverem corretas, mesmo uma análise bastante simples como a feita aqui, embora muito longe da perfeição, parece não ser completamente furada.
E você, leitor, leitora, quais os seus chutes? (Os dados brutos que usei para a análise estão aqui.) O Scienceblogs Brasil dará um exemplar de O Livro dos Milagres (de Carlos Orsi) para quem acertar o maior número de autores: saiba mais aqui.
--------
*A metodologia foi bastante simples - ainda que um tanto braçal. Foram contados (com ajuda da função de busca em processadores de texto) os números de palavras, parágrafos, linhas e pontuações. Parâmetros como tamanho de frase (dividindo-se o número de palavras pelo número de pontos), tamanho de parágrafo (dividindo-se o número de linhas pelo de parágrafos), índice de vírgulas (número de palavras sobre o de vírgulas), de parênteses, de dois pontos, de ponto e vírgula e de exclamações foram calculados e comparados: para cada par de blogue e texto do interCiência publicado, foi considerada a soma dos módulos das diferenças relativas entre os parâmetros. Se a complexidade for exatamente a mesma, a soma deve ser zero. Quanto maior a diferença, maior a soma.
Upideite(05/fev/2013): Aqui como seria a previsão final baseada unicamente em critérios de complexidade:
 Será? (Tem pelo menos um que muito provavelmente está errado, no entanto.)
Será? (Tem pelo menos um que muito provavelmente está errado, no entanto.)
Upideite(06/fev/2013): As chances de se acertar ao acaso ao autores dos textos:
0 (acerto): ~34%; 1: ~37%; 2: ~20%; 3: ~7%; 4: ~2%; 5: ~0,4%; 6: ~0,07%; 7: ~0,01%; 8: ~0,002%; 9: ~0,0003%; 10: ~0%; 11: 0% (exatamente 0, é impossível se errar somente 1); 12: 1/12! = 1/479.001.600
Abaixo, tabela com as previsões e os resultados do interCiência:

Figura 2. Análise de complexidade (parâmetros utilizados: tamanho de frase, de parágrafo, pontuações - vírgulas, dois pontos, ponto e vírgulas e exclamações). Em vermelho, valores acima de valor arbitrário de corte; em azul, valores abaixo de valores arbitrário de corte: quanto mais próximo de 0, mais similares os parâmetros de complexidade dos textos.
Em termos de complexidade*, o texto do interCiência publicado no blogue Rastro de Carbono (RC) é mais similar aos textos normalmente publicados no blogue SynbioBrasil (SB - e menos similar aos textos publicados aqui no GR). O texto no Ecce Medicus (EM) tem uma complexidade mais parecida com a dos textos do Caderno de Laboratório (CL - e mais diferente dos textos publicados no Rainha Vermelha - RV). E assim por diante.
Obviamente aqui é uma análise bastante simplificada. O tamanho amostral dos textos também é bastante limitado (10 textos normais dos blogues e apenas um texto do interCiência). É possível maior sofisticação, com calibração de pesos de cada fator - p.e., procedendo-se à maximização da verossimilhança com teste contra outros textos dos blogues - e uma amostragem mais ampla.
Veremos como esta análise se sai caso os verdadeiros autores dos textos sejam revelados futuramente. Algumas comparações podem ser feitas com outras informações:
1) a estrutura do texto publicado no RC é muito similar aos textos do SB (textos divididos por intertítulos e estes com determinado tamanho de fonte e em negrito);
2) o texto publicado no Curioso Realista (CR) está em português de portugal e, entre os participantes, é a variante usada nos textos do Ciência ao Natural (CN): a similaridade na complexidade, no entanto, não foi das maiores (na verdade, os textos de CN se aproximam mais ao texto publicado aqui no GR);
3) o texto no RV foi produzido por alguém ligado à microbiologia (além do próprio autor do RV, o autor do CR é microbiólogo): o índice de complexidade também não foi particularmente similar;
4) o único que trabalha com física entre os participantes da primeira rodada é o autor do CL; a similaridade maior é com o texto publicado no EM (que é sobre física; outro texto com a mesma temática foi publicado no próprio CL);
5) O texto publicado aqui no GR é mais similar aos textos do blogue 42 e a temática são exatamente curiosidades sobre o número 42;
6) O texto no SB foi escrito por alguém ligado à psicologia e à neurobiologia; entre os blogues participantes, são psicólogos os autores de O Divã de Einstein (DE) e de CogPsi (CP). Os textos de CP têm uma boa similaridade com o publicado no SB;
7) No CP, o texto é sobre psicologia, mas não é particularmente similar aos textos de DE (é mais similar aos textos de CR em complexidade);
8) No 42, o tema de sexo de animais e vídeos de aranhas remete ao RV; embora não seja particularmente similar no índice, a maior similaridade é com os textos do RV (e muito próximo com os do RC);
9) No Ciensinando (CE), o texto é sobre fisiologia, tema explorado no EM. Mas o valor não é muito similar, aproxima-se mais do 42.
Se essas informações estiverem corretas, mesmo uma análise bastante simples como a feita aqui, embora muito longe da perfeição, parece não ser completamente furada.
E você, leitor, leitora, quais os seus chutes? (Os dados brutos que usei para a análise estão aqui.) O Scienceblogs Brasil dará um exemplar de O Livro dos Milagres (de Carlos Orsi) para quem acertar o maior número de autores: saiba mais aqui.
--------
*A metodologia foi bastante simples - ainda que um tanto braçal. Foram contados (com ajuda da função de busca em processadores de texto) os números de palavras, parágrafos, linhas e pontuações. Parâmetros como tamanho de frase (dividindo-se o número de palavras pelo número de pontos), tamanho de parágrafo (dividindo-se o número de linhas pelo de parágrafos), índice de vírgulas (número de palavras sobre o de vírgulas), de parênteses, de dois pontos, de ponto e vírgula e de exclamações foram calculados e comparados: para cada par de blogue e texto do interCiência publicado, foi considerada a soma dos módulos das diferenças relativas entre os parâmetros. Se a complexidade for exatamente a mesma, a soma deve ser zero. Quanto maior a diferença, maior a soma.
Upideite(05/fev/2013): Aqui como seria a previsão final baseada unicamente em critérios de complexidade:
Upideite(06/fev/2013): As chances de se acertar ao acaso ao autores dos textos:
0 (acerto): ~34%; 1: ~37%; 2: ~20%; 3: ~7%; 4: ~2%; 5: ~0,4%; 6: ~0,07%; 7: ~0,01%; 8: ~0,002%; 9: ~0,0003%; 10: ~0%; 11: 0% (exatamente 0, é impossível se errar somente 1); 12: 1/12! = 1/479.001.600
Abaixo, tabela com as previsões e os resultados do interCiência:
Tabela 1. Desempenho da análise de complexidade na atribuição de autoria aos textos do interCiência.
| blogue | previsão | resultado | acerto |
| 42 | RC | ||
| CE | DE | EM | 0 |
| CL | GR | ||
| CN | CE | CE | 1 |
| CP | CR | 0 | |
| CR | RV | CN | 0 |
| DE | CN | 42 | 0 |
| EM | CL | ||
| GR | 42 | 0 | |
| RV | EM | CR | 0 |
| RC | SB | ||
| SB | CP | CP | 1 |
| total |



{kind=link}
4 comentários:
Acho que já dá para revelar a autoria. Em relação ao texto presenteado pelo CogPsi, acertou em cheio. O texto da SynBio fui eu que escrevi.
Salve, Marcus,
Valeu pela visita e pela informação.
Bem, a dica estava dada qdo você falou em microbiologia. Dentre os que participaram da primeira rodada do interCiência, creio que você era o único.
Mas a análise quantitativa (beeeem simplificada) do texto que fiz não levava em conta esse tipo de informação. Legal que tenha funcionado. Será que tem mais acertos?
[]s,
Roberto Takata
Opa, microbiologia, não, era neuropsicologia e psicobiologia. (Há outra psicóloga, mas que não trabalha com neuropsicologia, acho.)
[]s,
Roberto Takata
Postar um comentário